Note: Descriptions are shown in the official language in which they were submitted.
SYSTEM AND METHOD TO TRANSFORM A COMPLEX DATABASE INTO A
SIMPLE, FASTER AND EQUIVALENT DATABASE
Field of the Invention
[0001] The present disclosure relates to databases. In particular, the present
disclosure relates to a method for transforming a complex database into a
simpler, faster database, without losing information from the complex
database.
Background
10002] Modern database systems contain a large number of individual database
tables. As the size and complexity of modern software systems grow, so does
the need to store and maintain larger and larger sets of data. Database
systems
that contain hundreds to thousands of database tables are not uncommon.
Furthermore, the relationships between each of these tables can be multiple to
multiple, creating a complex web of logic that often becomes cumbersome and
difficult to maintain.
[0003] With respect to maintenance costs, the requirements to change the
structure of complex database systems often occurs annually or sooner for
large
companies. This effort requires the labor of database administrators and
programmers, all of which create significant labor cost.
[0004] Thus, it is desirable to develop a system and method for the automatic
translation of software system requirements from their source directly into a
self-
maintaining system ¨ capable of changing its structure in order to represent
any
database schema and data dynamically.
[0005] Such automation further reduces errors due to human factors or logical
inconsistencies.
1
Date Recue/Date Received 2020-06-15
[0006] The present disclosure overcomes these deficiencies of the prior art as
set
out below.
Summary
[0007] According to one aspect, there is provided a method for transforming a
database comprising a plurality of tables into a simple database, comprising:
providing a first table, said first table having an index column, a name
column, a
value column; providing a second table, said second table having an index
column and an elements column, wherein a second table entry in the second
table can be used in combination with the first table to reconstruct a row of
each
table of the database; for each table of the plurality of tables, determining
which
cells include references to other tables in the plurality of tables; for each
cell of
each table of the database which does not include a reference to other tables
in
the plurality of tables: creating a first table entry in the first table,
wherein the
name column includes a column heading of the cell, the value column includes a
value of the cell, the first table entry having an index; and updating the
second
table entry corresponding to the row of the cell of the table of the database
to
include the index of the first table entry; and for each cell of each table of
the
database which does include a reference to other tables in the plurality of
tables:
determining a reference entry in the second table, the reference entry
corresponding to the reference, wherein said determining a reference entry in
the
second table comprises: finding, in the second table, an entry which includes
an
index of a key entry in the first table, the key entry in the first table
having a name
corresponding to the key value and a value corresponding to the value of the
cell;
creating a first table entry in the first table, wherein the name column
includes a
column heading of the cell, the value column includes the index of the
reference
entry, the first table entry having an index; and updating the second table
entry
corresponding to the row of the cell of the table of the database to include
the
index of the first table entry.
2
Date Recue/Date Received 2020-10-26
[0008] According to another aspect, there is provided a computer readable
medium storing computer readable instructions thereon that when executed by a
computer perform the method described in the preceding paragraph herein.
Brief Description of the Drawings
[0009] The present application will be better understood with reference to the
drawings, in which:
[0010] Figure 1 is a block diagram representing the logical relationship
between
groups and elements according to at least one embodiment of the present
disclosure.
[0011] Figure 2 is a block diagram of a method for resolving a group according
to
at least one embodiment of the present disclosure.
[0012] Figure 3 is a binary tree representation of a group according to at
least
one embodiment of the present disclosure.
[0013] Figure 4 is a block diagram of a method for transforming a database
according to at least one embodiment of the present disclosure.
[0014] Figure 5 is a block diagram of a method for transforming a database
according to at least one embodiment of the present disclosure.
3
Date Recue/Date Received 2020-10-26
Detailed Description
[0015] The present disclosure provides for a method and system for
transforming
a complex database into a simpler and faster database, as described in detail
below.
[0016] For the purposes of the present disclosure, the term "input database"
will
be used to denote the complex database before transformation. The term "input
table" will be used to denote tables of the input database.
[0017] The system and method of the present disclosure are applicable to any
arbitrary input database, regardless of the number of tables or their
relationship
to each other. All information, including relational information, is preserved
during transformation.
[0018] However, the output database does not include an arbitrary number of
tables. Rather, the output database includes an Element table and a Group
table. In some embodiments, the output database further includes a Group-Link
table, and a Binary-Elements table. Each of these are described in detail
below.
[0019] An element represents the simplest data item of the present system. In
particular, each element of the Element table corresponds to a single value
from
an object in the input database.
[0020] For example, let us consider an input database comprising a table
describing airline flights, shown below as Table 1. Each row of Table 1
corresponds to a flight object, and each flight object is described by a
flight
number, a city of departure, a city of arrival, and a date.
4
Date Recue/Date Received 2020-06-15
Flight No. Departure Arrival Date
213 Ottawa Montreal 10/17/2012
451 Toronto Vancouver 10/18/2012
127 Winnipeg Calgary 10/19/2012
632 Halifax Edmonton 10/20/2012
Table 1
[0021] As can be seen from the corresponding Element table, each cell in Table
1
corresponds to a row of the Element table.
identity name value
group_identity
1 Flight No. 213 00001
2 Flight No. 451 00002
3 Flight No. 127 00003
4 Flight No. 632 00004
5 Departure Ottawa 00001
6 Departure Toronto 00002
7 Departure Winnipeg 00003
8 Departure Halifax 00004
9 Arrival Montreal 00001
Arrival Vancouver 00002
11 Arrival Calgary 00003
12 Arrival Edmonton 00004
13 Date 10/17/2012 00001
14 Date 10/18/2012 00002
Date 10/19/2012 00003
16 Date 10/20/2012 00004
Element Table 1
5
Date Recue/Date Received 2020-06-15
[0022] As seen from the above, the Element table includes 4 columns, namely
identity, name, value and group_identity. The identity is an index used to
reference any element from the Element table. The name identifies the column
in the input table from which the value originates. The value includes the
value of
the element as it appears in the input table, and the group_identity
identifies the
object to which the value belongs in the input table, as is described below.
[0023] A group corresponds to an object in the input database and comprises
each of the elements derived from that object. An exemplary Group table
corresponding to Table 1 is shown below.
group identity Elements
00001 (1, 5, 9, 13)
00002 (2,6, 10, 14)
00003 (3, 7, 11, 15)
00004 (4,8, 12, 16)
Group Table 1
[0024] As seen above, each group comprises a group_identity, as an index to
address any group within the Group table. Moreover, the Group table comprises
a list of elements, identified by their respective identity, or index.
[0025] Notably, it can be shown that Table 1 can be reconstructed from the
Element and the Group table above. Accordingly, no information was lost in the
transformation.
[0026] Specifically, by starting with group 1, one finds elements 1, 5, 9 and
13.
Going to the Element table, one finds that element 1 corresponds to Flight No.
213, element 5 corresponds to Departure from Ottawa, element 9 corresponds to
Arrival in Montreal, and element 13 corresponds to a date of 10/17/2012.
Therefore, group 1 correctly reconstructs the first row of Table 1. A similar
6
Date Recue/Date Received 2020-06-15
process can be used to reconstruct the subsequent rows of Table 1, based on
groups 2, 3 and 4.
[0027] Groups can also be elements. This is useful, as in many existing
databases, the attribute of an object may not have a discrete value, but
rather
have an object as a value.
[0028] In particular, considering the above example, let us consider that the
input
database further includes a customer table, as shown below.
Customer Number Name Flight No.
101 John Doe 451
102 Bill Smith 213
103 Emma Jones 632
Table 2
[0029] As with Table 1 above, Table 2 may be transformed in groups and
elements. However, during transformation there is no need to create individual
group and element tables for each input table. Rather, new groups and elements
are simply appended on the existing Group table and Element table.
[0030] As will be appreciated by those skilled in the art, Table 2 includes a
"Flight
No." column, which corresponds to the "Flight No." column in Table 1. In this
particular case, "Flight No." functions as a key for Table 1, as each Flight
No.
uniquely identifies a single flight (for the purposes of this example), and
may be
used by other tables to reference a flight object.
[0031] Because "Flight No." is a key for Table 1, when an element with name
"Flight No." is encountered in a separate table, the element's value will not
be the
discrete value, but rather the group corresponding to the flight object having
a
Flight No. of the discrete value. This is illustrated in the Element table
below.
7
Date Recue/Date Received 2020-06-15
identity name value
group_identity
17 Customer Number 101 00005
18 Customer Number 102 00006
19 Customer Number 103 00007
20 Name John Doe 00005
21 Name Bill Smith 00006
22 Name Emma Jones 00007
23 Flight group_identity:00002 00005
24 Flight group_identity:00001 00006
25 Flight group_identity:00004 00007
Element Table 2
[0032] Notably, the value for elements 23, 24 and 25 are group identifiers.
These
groups are identified based on a method discussed below with respect to Figure
5.
[0033] Table 2 further adds to the Group table, as shown below.
group_identity Elements
00005 (17, 20, 23)
00006 (18, 21,24)
00007 (19, 22, 25)
.. Group Table 2
[0034] From the Group table, we see that the group with group_identity 00005
includes elements 17, 20, and 23. To resolve this group, we first look at the
Elements table at element 17 and find Customer Number 101. Then we look at
the Elements table at element 20 and find the Name "John Doe". Then we look
at the Elements table at element 23 and find the Flight group_identity:00002.
8
Date Recue/Date Received 2020-06-15
[0035] Because the last element of group_identity 00005 is also a group, it
must
be resolved in a similar manner. Thus, we look at the Group table and find
that
group_identity:00002 includes elements 2, 6, 10 and 14. By a look-up in the
Element table, we see that these elements correspond to Flight No. 451, whose
Origin is Toronto and whose Destination is Vancouver on the date of
10/18/2012.
[0036] Thus, we know that John Doe, Customer Number 101 will be a passenger
on Flight No. 451 from Toronto to Vancouver on 10/18/2012.
[0037] As seen above, groups can be elements, and can be a member of another
group. For example, element 23 is a group, and is itself the member of a
group.
According to the present nomenclature, element 23 is a sub-group, because it
is
a group which is part of a group.
[0038] The present Group and Element tables contain all the information
necessary to determine who is/are the parent/children of a particular group.
For
example, based on the entry in the column group_identity for element 23, we
see
that the parent group is group 5. Moreover, based on the entry in the value
column for element 23, we see that element 23 corresponds to
group_identity:00002. Going into the Groups table, we see that
group_identity:00002, namely element 23, includes the elements 2, 6, 10, and
14. Going back to the Elements table we see that none of elements 2, 6, 10 and
14 are sub-groups.
[0039] However, it is useful to be able to provide the parent/children of a
particular group without having to resolve the elements through the Group and
Element table as shown above. Therefore, according to at least some
embodiments, the system includes a Group-Link table, which includes the
.. parent/children relationships between the groups. A Group-Link table based
on
the above example is provided below.
9
Date Recue/Date Received 2020-06-15
parent_identity children_identity
00001 0
00002 0
00003 0
00004 0
00005 (group_identity:00002)
00006 (group_identity:00001)
00007 (group_identity:00004)
Group Link Table 1
[0040] As seen in the above Group-Link table, groups 00001 to 00004 have no
children, and groups 00005 to 00007 have 1 child each. However, in a more
complex example, one would expect to have groups with multiple children.
[0041] In a further embodiment, the Group-Link table may include a link to a
group's parents as well, as shown with reference to Group Link Table 2 below.
group_identity children_identity
parent_identity
00001 0
(group_identity:00006)
00002 0
(group_identity:00005)
00003 0 0
00004 0
(group_identity:00007)
00005 (group_identity:00002) 0
00006 (group_identity:00001) 0
00007 (group_identity:00004) 0
Group Link Table 2
[0042] Notably, a group may have multiple parents as well, even if in the
above
example only shows groups having a single parent.
Date Recue/Date Received 2020-06-15
[0043] In some cases, elements are not related to data which can be
represented
as text. For example, one element could relate to an image, such as the photo
of
an individual. These elements are stored in the Element-Binary table, which is
designed to hold Binary Large Objects (BLOBs), and referenced in the Elements
table.
[0044] Further to the airline example above, let us consider a table of pilots
from
an airline, in which the photo of the pilots is included as a column in the
table.
Pilot_ld Name Airline Photo
12345 Frodo Baggins Middle Air
I
Table 3
[0045] As in the above example, the items in the Pilot_ld, Name, and Airline
columns are provided as elements in the Element table. Notably however, the
item in the Photo column is provided in the Element table, but the value of
this
element will be a reference to the Element-Binary table, which will include
the
relevant image.
[0046] Element Table 3 below is a continuation of the Element table based on
Table 3.
11
Date Recue/Date Received 2020-06-15
identity name value
group_identity
26 Pilot_ld 12345 00008
27 Name Frodo Baggins 00008
28 Airline Middle Air 00008
29 Photo element-binary:00001 00008
Element Table 3
[0047] The above would further imply additions to the Groups table, but these
are
omitted for the purposes of the present disclosure. An Element-Binary table
based on the above is shown below.
index data
00001
I
Element-Binary Table 1
[0048] The Element-Binary table simply includes an index, and the relevant
BLOB in the data column.
[0049] The above has demonstrated that an input database with an arbitrary
number of tables can be converted into an Element Table and a Group Table.
Furthermore, in some embodiments, the Element Table and Group Table are
supplemented with a Group-Link table, and/or, an Element-Binary table.
[0050] This section will examine the algorithm complexity of resolving objects
using the Element Table and the Group Table. Specifically, it will be
12
Date Recue/Date Received 2020-06-15
demonstrated that any object may be viewed as a binary tree, and that
resolving
an object consists of performing a tree traversal.
[0051] Let C be the set of all databases. Let C' subset of C be the set of all
structured query databases, e.g. SQL for relational databases. Let A represent
the present method, as described in the present disclosure, and let B
represent
the set of all other methods for structured queries on the set C'. We will
show that
for meaningful queries on finite sets, the worst-case performance of A is
better
than the worst-case performance of B.
[0052] A query is order-independent if the ordering of objects in the
structure
does not affect the results of the query. The present method is constructed
for
order-independent queries.
[0053] Define the class called Elements to be the class constructed of
the attributes. Define the class called Groups as a subclass of Elements, and
thereby inheriting from Elements. Furthermore, instances of Groups contain
instances of Elements. We will assume that the number of objects defined as
Groups, m, and the number of objects defined as Elements, n, are both finite.
According to the present method, instances of the class Groups are stored in
the
Group table, and instances of the class Elements are stored in the Element
table.
[0054] We allow for a group to be one of the elements of another group. Thus,
we
establish a two directional connection between the Group table and the Element
table, one direction from the Group table to the Element table joining an
element
of each group to its respective group, and the other direction from the
Element
table to the Group table, allowing for a group to be an element of another
group.
See Figure 1 for an example.
[0055] Consider a schema S as a labeled directed tree, where the nodes
represent groups or elements, and the links represent the relationships
between
13
Date Recue/Date Received 2020-06-15
the nodes. We assume that every node is a child of another node, except for
the
root. Define the ancestors of a node v to be all the nodes along the path from
the
root to the node v. Define the descendants of a node v to be all nodes vi, ...
, vk
such that v is their ancestor. The level of a node is defined by letting the
root be
at level one. If a node is at level I, then all of its children are at level I
+ 1. The
depth of a tree is defined as the maximum level of any node in the tree.
[0056] Starting from a given group Gl, the present method starts from the
group
G1 in the Group table and finds all of the elements El, ..., Ek linked to Gl.
If
there are no groups among El, ..., Ek, the program returns this set as the
output.
[0057] Otherwise, if there exists an element Ei such that Ei = Gj, the
algorithm
goes along the path (link) from node Ei to node Gj . Subsequently, the
algorithm
finds all nodes that are linked to Gj , and this continues until all of the
nodes that
are linked in this manner are found. We assume that throughout this algorithm,
if
an object has been retrieved once, it will not be retrieved again. That is, if
Gi, for
some i, has already been retrieved as one of the elements of a node in
previous
steps, it will not be retrieved again as one of the elements of another node,
even
if it belongs to this second set of elements. This assumption eliminates any
possibility of the algorithm to not terminate.
[0058] For the purpose of algorithmic analysis, we use the tree representation
as
defined above. We start by constructing the rooted tree generated from the
query
Q made by the user. Next, node G1 corresponding to Q is visited. Afterwards,
all
descendants of G1 get visited. The output of the algorithm is the subtree
rooted
at Gl. This can be achieved by using any of the common methods for tree
traversal. Note that a subtree rooted at a vertex v, is itself another rooted
tree.
For example, consider lnorder traversal. lnorder traversal consists of moving
down the tree towards the left until you cannot go any further. Then, visit
the
node, and move one node to the right and continue in the recursive manner.
Note
that lnorder traversal can be represented in a non-recursive manner. For a
tree
of n nodes, it can be shown that the space required for non-recursive inorder
14
Date Recue/Date Received 2020-06-15
traversal is at most n and the time complexity is of 0(n), as described in
Fundamentals of Data Structure in C++, Computer Science Press, New York,
1995, by Horowitz, Sahni and Mehta.
[0059] Note that it is sufficient to construct the model using binary trees.
This
claim is supported by the fact that any k-ary tree can be transformed into a
binary
tree, using the method known as "Left Child-Right Sibling Representation", as
described below.
[0060] Consider a binary tree T. The maximum number of nodes at each level i
is 2" for i greater than or equal to 1. Thus, the maximum number of nodes in a
binary tree of depth k is 2k - 1. It can be shown that the height of a
complete
binary tree with n nodes is [10g2(n + 1)].
[0061] Standard complexity analysis includes measuring how run time grows as a
function of input size. Note that for a database, this means we will use
Boolean
(yes/no) queries to eliminate dependence on output size, and the input size is
equal to database size plus query size.
[0062] We use conjunctive queries which are the most common SQL queries
(Select-Project-Join). It has been shown, in Chandra, A.K., Merlin, P.M.,
Optimal
Implementation of Conjunctive Queries in Relational Data Bases, Proceedings of
the ninth annual ACM symposium on Theory of computing, 1977, that the
combined complexity of conjunctive queries is NP-complete.
[0063] Evaluation of large conjunctive queries is a difficult problem for
databases.
This is mainly due to the fact that the database is required to evaluate a
long
sequence of joins and projections. Thus, the query optimizer has to search a
very large space and continuously move from one table to another, which may
result in a great amount of time/space to finish the query.
Date Recue/Date Received 2020-06-15
[0064] Using the present method, the need for constructing several tables is
eliminated through an efficient construction of only two tables, namely the
Group
table and the Element table. As discussed above, all queries can be found by
moving along these two tables, which can also be viewed as a tree traversal.
Tree traversal can be accomplished in 0(n) which is a great reduction from the
typical time and space required by methods using multiple tables.
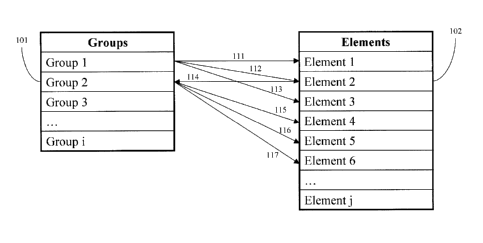
[0065] Reference is made to Figure 1, which includes a Group table 101 and an
Element table 102. Groups table 101 lists groups 1 to i, and Elements table
102
lists elements 1 to j.
[0066] As represented by arrows 111, 112 and 113, group 1 includes elements 1,
2 and 3. Further, as represented by arrow 114, element 2 is group 2.
Similarly,
as represented by arrows 115, 116 and 117, group 2 includes elements 4, 5 and
6.
[0067] As would be appreciated by those skilled in the art, Figure 1 describes
a k-
ary tree, in which groups 1 and 2, and elements 1 to 6 are the nodes, and in
which the arrows are the branches.
[0068] More specifically, the method for resolving a given group G is
described
with reference to Figure 2.
[0069] The method starts at 200 and proceeds to block 210 in which the
elements
of group G are retrieved. At block 220, the method iterates over every element
of
group G, ending at block 250. At block 230, if an element is not a group, the
value of the element is retrieved at block 240. If an element is a group, the
method proceeds back to block 210 in which the elements of that group are
retrieved.
16
Date Recue/Date Received 2020-06-15
[0070] Accordingly, a group may be resolved recursively based on the method
shown in Figure 2. Notably, if a group includes elements which also include
the
parent group, the method of Figure 2 will run indefinitely. Accordingly, when
an
element is retrieved at bock 240, a check is made to ensure that the element
was
not already retrieved previously, thereby preventing endless loops.
[0071] According to at least one embodiment, instead of a k-ary tree as shown
in
Figure 1, a binary tree is constructed from the Groups and Elements tables. In
particular, any k-ary tree can be transformed into a binary tree using "Left
Child-
Right Sibling Representation", as is known in the art and described in
Fundamentals of Data Structure in C++, Computer Science Press, New York,
1995, by Horowitz, Sahni and Mehta.
[0072] Figure 3 shows a binary tree constructed using Left Child-Right Sibling
Representation from the k-ary tree of Figure 1.
[0073] In a binary tree constructed using Left Child-Right Sibling
Representation,
the left child of a node in a binary tree corresponds to the leftmost child
(if any) of
that same node in the k-ary tree, and the right child of a node in a binary
tree
corresponds to the closest right sibling (if any) of that same node in the k-
ary
tree.
[0074] The method for converting an arbitrary database into a simple database
will now be described from a general perspective. The input database contains
n
tables. Each table includes a key value, which uniquely identifies each
element
within the table.
[0075] In at least some embodiments, the input database is provided with a
list of
key values. In at least another embodiment, the key value of a table is
provided
in the first column of the table. However, other means of identifying the key
value
of a table are known and the present disclosure is not so limited.
17
Date Recue/Date Received 2020-06-15
[0076] Notably, while the key value of a table is known, in most cases it will
not
be apparent under what heading the key values appear in a different table. For
example, as seen above, the key value of Table 1 is "Flight No.", and this
value is
referenced in a subsequent table under the heading "Flight No.". In this case,
the
headings are the same, however this is not necessarily the case. In order to
ensure that the proper linkage is created between "Flight No." in Table 1 and
"Flight No." in Table 2, an analyst or a programmer may be required to
manually
provide the linkage information to the system. As such, when a table
references
a key value from another table, it is known by the transformation process.
[0077] Reference is now made to Figure 4 which shows a block diagram of the
first stage of the transformation process.
[0078] A first table is selected from the input database. For each object or
row in
the table, the process of Figure 4 is performed.
[0079] The process starts at 400 and proceeds to block 410 in which a group is
created in the Group table, but the "Elements" column in the group table is
not
populated.
[0080] At block 420, the i-th cell in the row is read. At block 430, if the
value of
the element is not a group, that is, if the column of the current cell is not
linked to
a key value from another table, the process proceeds to block 440 in which an
element is created with a unique identity, a name corresponding to the column
heading, the value of the cell, and the group identity based on the group
created
for the object or row. If the value is a binary object, an entry is created in
the
Element-Binary table and the value stored in the Element table is a reference
to
this entry.
18
Date Recue/Date Received 2020-06-15
[0081] If the value of the element is a group, that is, if the column of the
current
cell is linked to a key value from another table, no element is created at
this
stage.
.. [0082] At block 450, a check is made to see if the current cell is the last
cell in the
row. If not, i is incremented at block 470 and the process goes back to block
420
to read the next cell in the row.
[0083] If all cells in the row were processed, the group is updated with the
index
values of the newly created elements at block 460, and the process ends at
block
480.
[0084] This is repeated for each table in the input database.
[0085] At this stage, conversion of the database is complete except for the
missing values for elements which correspond to groups. These are filled-in
with
a process described in Figure 5.
[0086] Notably, in order to fill-in the missing values, the process will
iterate
through the tables of the input database a second time. As it does so, it
should
be able to keep track of which elements and which groups created in the first
stage correspond to any given object or cell of a table from the input
database.
This can be accomplished by various means.
[0087] For example, in one embodiment the iteration through each table of the
input database could be performed in the exact same order as during the first
stage of the process. As groups and elements are added to the Group and
Element tables in sequence, this would allow the process to associate objects
or
cells of the input table with groups or elements.
19
Date Recue/Date Received 2020-06-15
[0088] In another embodiment, group and element information are added to the
input database, without otherwise modifying the input database, so that as the
process iterates through its tables a second time, corresponding group and
element information is available to the process.
[0089] In yet another embodiment, information linking objects and cells of the
input database with groups and elements is stored in a separate data structure
which may be queried by the process.
[0090] Other means of ensuring that this information is available during the
second stage of the process would be apparent to those skilled in the art, and
the
present disclosure is not so limited.
[0091] The second stage of the conversion process is illustrated in Figure 5
and
is performed for every cell of the input database. The process starts at block
500
and proceeds to block 510 in which a cell is read from the input table. At
block
520 it is determined whether the cell includes a key value from another table.
If
not, the cell has already been transformed in the first stage, and the process
ends at block 590.
[0092] If the cell includes a key value from another table, a new element
pointing
to the correct group is created, and the parent group of this element is
updated to
reflect the creation of this new element. The parent group is known from the
association between groups and objects created during the first stage of the
transformation. The group to which the new element should point to is
identified
by a search.
[0093] At block 530, the i-th group is read from the Group table. At block
540, if
this group does not include an element with the key value, i is incremented at
block 560 and the process returns to block 530 to read the next group from the
Group table.
Date Recue/Date Received 2020-06-15
[0094] At block 540, if the group does include an element with the key value,
the
value of the cell and the element are compared at block 550. If these values
do
not match, i is incremented at block 560 and the process returns to block 530
to
read the next group from the Group table.
[0095] If the values match, the process proceeds to block 570 in which a new
element is created whose value is the group identity of the i-th group of the
table.
As in the first stage, the name of the new element corresponds to the column
heading for the current cell, and the group identity of the new element is the
parent group.
[0096] Then, at block 580, the parent group is updated to reflect the creation
of
the new element, and the process ends at block 590.
[0097] In at least some embodiments, the Group-Link table is created after the
creation of the Group table and the Element table. The data in the Group-Link
table can be derived easily from the data in the Group Table and the Element
table.
[0098] The subject matter of the present disclosure may be practiced on any
computing device as is known in the art and the present disclosure is not so
limited. According to at least one embodiment, the present system and method
may be performed on a computing device comprising a processor, random-
access memory (RAM), and sufficient storage to store the relevant data.
[0099] In at least one embodiment, the present system and method are
implemented on a server residing on a network, such as a local area network
(LAN) or a wide area network (WAN).
21
Date Recue/Date Received 2020-06-15